















Generative AI
Build your own AI models and apps like ChatGPT for next-level growth

Our experts have decades of experience in various industries.Our experts have decades of experience in various industries. Talking to them is free and comes with no obligations to sign up with us.
Our experts have decades of experience in various industries.Our experts have decades of experience in various industries. Talking to them is free and comes with no obligations to sign up with us.

Why Web Scraping Alone Is No Longer Enough for Modern Businesses?
Web scraping is an effective way to gather data from websites, but businesses are increasingly seeking more advanced methods of …
Parth Vataliya
Reading Time: 10 min
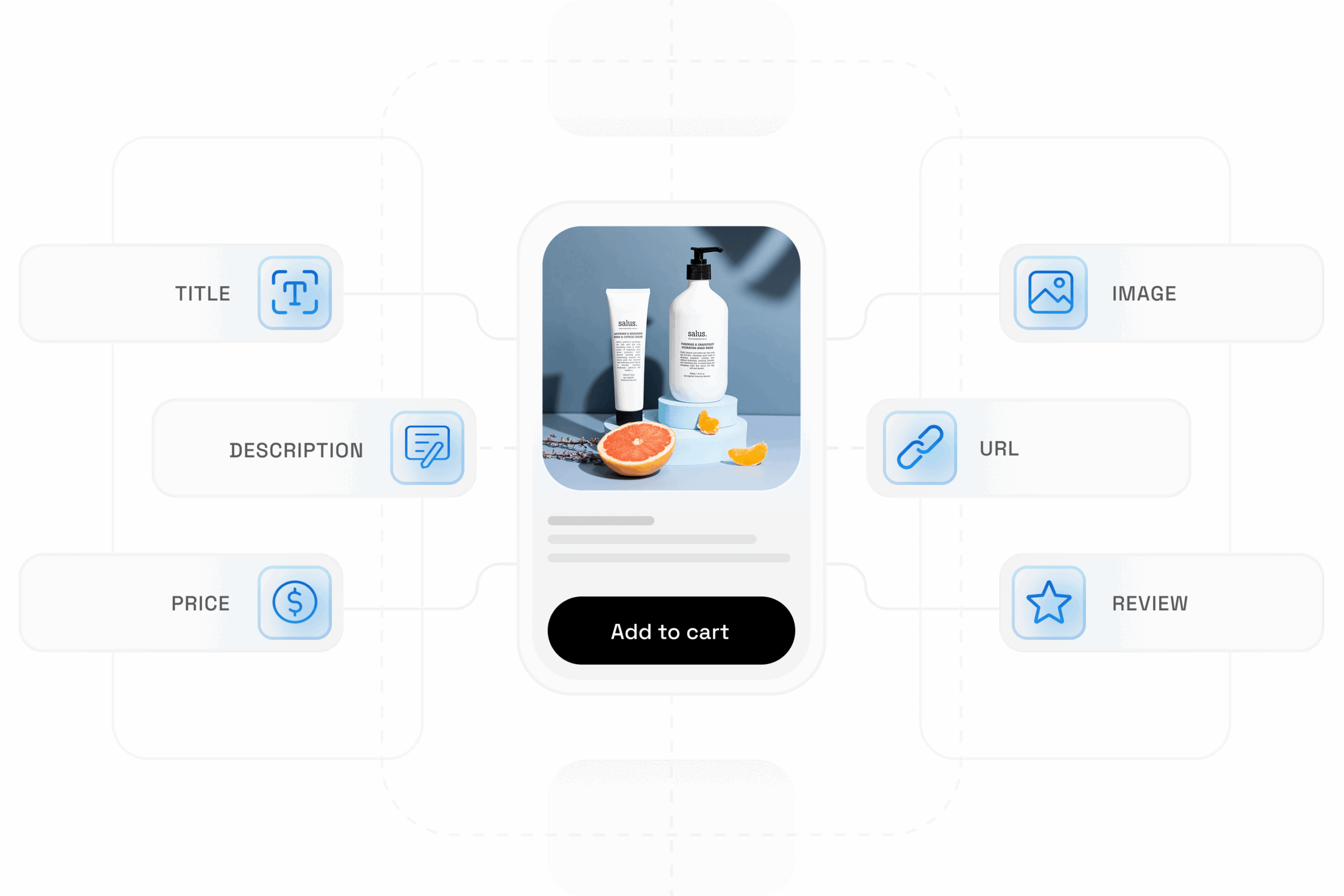
How to Scrape Personal Care & Beauty Product Data from Sephora.com?
Sephora.com hosts over 300 brands and thousands of beauty products. Extracting this data helps businesses analyze pricing trends, track competitor …
Parth Vataliya
Reading Time: 13 min
How to Extract AI Overviews for Multiple Queries: A Technical Guide
What Are AI Overviews and Why Should You Extract Them? AI Overviews represent Google’s latest innovation in search technology. These …
Parth Vataliya
Reading Time: 10 min

What is the Role of Web Scraping in Predictive Analytics?
P1 A simple, one-paragraph explanation: “Amazon data scraping, or web scraping, is the automated process of extracting public information from …
P1 A simple, one-paragraph explanation: “Amazon data scraping, or web scraping, is the automated process of extracting public information from …
Parth Vataliya
Reading Time: 1 min

From Data to Dollars: A Case Study on Scaling a Reselling Business with Facebook Scraping
Discover how Facebook scraping helped scale a reselling business. This case study reveals data-driven strategies to boost growth, sales, and …
Discover how Facebook scraping helped scale a reselling business. This case study reveals data-driven strategies to boost growth, sales, and …
Parth Vataliya
Reading Time: 1 min
What is the Role of Web Scraping in Predictive Analytics?
P1 A simple, one-paragraph explanation: “Amazon data scraping, or web scraping, is the automated process of extracting public information from …
P1 A simple, one-paragraph explanation: “Amazon data scraping, or web scraping, is the automated process of extracting public information from …
Parth Vataliya
Reading Time: 1 min
Get in Touch with Us
iWeb Scraping eliminates manual data entry with AI-powered extraction for businesses.

Address
Web scraping is an efficien
Address
Web scraping is an efficien
Address
Web scraping is an efficien
Address
Web scraping is an efficien
Expert Consultation
Discuss your data needs with our specialists for tailored scraping solutions.
Expert Consultation
Discuss your data needs with our specialists for tailored scraping solutions.
Expert Consultation
Discuss your data needs with our specialists for tailored scraping solutions.
